
Bugün, bir konuk katkısını sunmaktan mutluluk duyuyoruz. laurent ferrara (Paris Skema Business School’da Ekonomi Profesörü ve Uluslararası Tahminciler Enstitüsü).
Dünyanın dört bir yanındaki son ekonomik, finansal ve salgın krizler dizisi, makroekonomik tahminciler için tahmin ufkunu önemli ölçüde kısalttı. Covid-19 krizinin merkezinde, ilgi ufku iki yıl öncesinden çok hafta sonuydu. Bu, uygulayıcıların yeni tür yüksek frekanslı ve alternatif veri kümelerine odaklanmasına yol açarak ekonometriciler için yeni zorluklar ortaya çıkardı (yapılandırılmamış veriler, çok büyük veri kümeleri, karışık frekanslar, yüksek oynaklık, kısa örnekler…).
Son literatürde, örneğin web kazıma verileri, tarayıcı verileri veya uydu verileri gibi çeşitli alternatif veri kaynakları kullanılmıştır. Genel olarak, bu veri kümeleri son derece büyüktür ve Büyük veri. Alternatif verilerin ana kaynaklarından biri Google arama verileridir ve bu tür verilerin tahmin için kullanımına ilişkin ufuk açıcı makaleler Hal Varian ve ortak yazarlarınkilerdir (örneğin bkz. Burada). Şimdilik tahmin/tahmin alanında, literatür, Google verileri için, en azından işsizlik oranı (D’amuri ve Marcucci, 2017) istihdamda (Borup ve Montes Schutte, 2020), inşaat izinleri (Coble ve Pincheira, 2017) veya araba satışları (Nymand ve Pantelidis, 2018). Bununla birlikte, diğer bilgi kaynaklarıyla doğru bir şekilde karşılaştırıldığında, jüri, ekonomistlerin tahmin ve tahmin için Google verilerini kullanmaktan elde edebileceği kazanç konusunda hâlâ yetersizdir. Econbrowser’da oldukça tartışılan bir yan soru, bu verilerin uygulayıcılar tarafından tekrarlanabilirliği hakkındadır (bkz. Burada Hal Varian ve Simon van Norden arasındaki bir tartışma için).
Yakın zamanda yayınlanan bir makalede, Anna Simoni içinde İşletme ve Ekonomi İstatistikleri Dergisi (buraya bakın bir taklitçi), genellikle tahminciler tarafından kullanılan kamuoyu anketleri veya imalat üretimi gibi resmi değişkenleri kontrol ederken, Google verilerinin üç aylık GSYİH büyümesini tahmin etmede hala yararlı olup olmadığını kendimize soruyoruz. Ve eğer öyleyse, bu alternatif veriler tam olarak ne zaman tahmin doğruluğunda bir kazanç sağlıyor? GSYİH büyümesini önceden tahmin etmek, politika yapıcıların makroekonomik koşulları gerçek zamanlı olarak değerlendirmeleri için son derece yararlıdır. Makroekonomik tahmin kavramı şu kişiler tarafından popüler hale getirilmiştir: Giannone ve ark. [2008] ve mevcut makroekonomik koşulları yüksek frekans bazında değerlendirmeyi amaçlaması yönüyle standart tahmin yaklaşımlarından farklıdır. Buradaki fikir, her zaman gecikmeli olarak ortaya çıkan resmi Üç Aylık Ulusal Hesapların yayınlanmasından önce politika yapıcılara ekonominin durumunun gerçek zamanlı bir değerlendirmesini sağlamaktır. Örneğin bkz. Burada ABD ekonomisi için ve Burada Econbrowser’daki son gönderi için.
Google arama verileri yüksek boyutlu olduğundan, değişken sayısının zaman serisi boyutuna göre büyük olması anlamında, bunları kullanmanın bir bedeli vardır: ilk olarak, boyutsallıklarını çok yüksekten yükseğe indirmemiz gerekir. bir tarama prosedürü kullanarak ve ikincisi, önceden seçilmiş değişkenlerle başa çıkmak için düzenli bir tahmin edici kullanmamız gerekiyor. Düzenlileştirme teknikleri, potansiyel olarak ilişkili olan birçok değişkeni doğrusal bir regresyonda hesaba katmanın bir yoludur (örneğin bkz. Ridge tahmini). Bu bağlamda, değişken ön seçimi ve Ridge düzenlileştirmeyi birleştirerek büyük bir veri tabanını hesaba katan yeni bir yaklaşım ortaya koyduk. Makalede, bu tahmin stratejisinin iyi asimptotik özelliklerine ilişkin bazı teorik sonuçlar sunuyoruz. Model Seçiminden Sonra Mahya.
Bu teorik sonuçlara ek olarak, makroekonomik tahmin için yüksek boyutlu alternatif verileri kullanmakla ilgilenen insanlarla paylaşmak için ilginç olabilecek bir dizi ampirik sonuç elde ediyoruz. Hedefimiz, çeyreğin her haftasında ABD, avro bölgesi ve Almanya için 3 tür ekonomik dönem üzerinden GSYİH büyümesini tahmin etmektir: (i) sakin bir dönem (2014-16), (ii) ani bir aşağı kaymanın olduğu bir dönem GSYİH büyümesi (2017-18, ABD ile Çin/Avrupa arasındaki ticaret savaşıyla bağlantılı) ve (iii) büyük negatif büyüme oranlarına sahip bir durgunluk dönemi (2008-09, Küresel Mali Krizin neden olduğu). Bu bağlamda, klasik makro verileri (anketler ve üretim) ve Google’dan gelen alternatif verileri (zaten kategoriler ve alt kategoriler halinde gruplandırılmış Google Arama Verileri) kullanıyoruz. Çeşitli yaklaşımları, Tahmin Hatasının Ortalama Karekökü (RMSFE) ile ölçüldüğü üzere, şimdi tahmin etme yeteneklerine dayalı olarak karşılaştırıyoruz. Ampirik analizimizden dört göze çarpan gerçek ortaya çıkıyor.
İlk olarak, standart bir regresyonu (Ridge düzenlemesi ile) ön seçimden sonraki bir regresyonla (bizim Model Seçiminden Sonra Mahya yaklaşmak). Şekil 1, sakin bir dönemde (2014-16) Euro bölgesi için sonuçları göstermektedir. Modele girmeden önce ön seçim verilerinin şimdi tahmini doğruluğu açısından kazancı açıkça görüyoruz. Buradaki fikir, çok fazla değişkene sahip olmanın çok fazla gürültü çıkarmasıdır. Bazıları doğrudan ekonomik faaliyetle ilgili olmadığından, bu özellikle Google Arama Verileri için geçerlidir. Bu sonuç, dinamik faktör modellerinin arka planına karşı önceki sonuçları doğrular (bkz. Bai ve Ng, 2008 veya Barhoumi ve diğerleri, 2009).
Şekil 1: Sakin bir dönemde (2014-16) Euro bölgesi için RMSFE’ler, Ridge düzenlemesi (mavi çubuklar) ile standart bir regresyondan ve Model Seçimi sonrası Ridge yaklaşımından (turuncu çubuklar) kaynaklanmaktadır. Mevcut çeyreğin 13 haftasında RMSFE’lerin gelişimi. Kaynak: Ferrara ve Simoni (2023)
İkinci olarak, Google arama verilerinin, çeyreğin ilk dört haftası için, yani cari çeyreğin durumu hakkında resmi bir bilgi olmadığı zaman için GSYİH büyüme oranını tahmin etmedeki yararlılığına dikkat çekiyoruz. Şekil 1’de, çeyreğin başında (1. haftadan 4. haftaya kadar) Google verilerinin, RMSFE’lerin oldukça düşük (%0,2 ile %0,3 arasında) olması anlamında gerçekten de GSYİH büyüme oranının doğru bir resmini sunduğunu görüyoruz. , tüm bilgilerin mevcut olduğu çeyreğin sonundaki değerlerden biraz daha yüksek (yaklaşık %0,2).
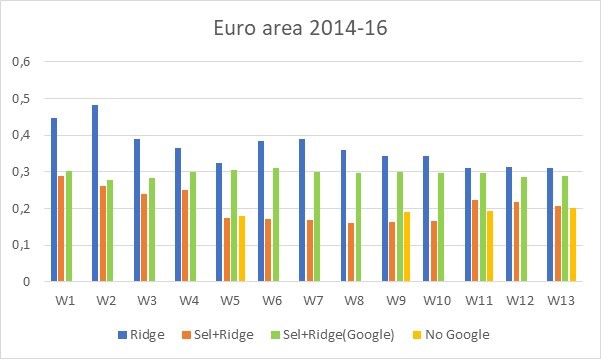
Şekil 2: Sakin bir dönemde (2014-16) Avro bölgesi için RMSFE’ler, Ridge düzenlemesi (mavi çubuklar) ile standart bir regresyondan, Model Seçiminden Sonra Ridge yaklaşımından (turuncu çubuklar), yalnızca Google verilerini kullanan Model Seçiminden Sonra Ridge yaklaşımından kaynaklanmaktadır. (yeşil çubuklar) ve herhangi bir Google verisi olmayan temel bir regresyon modelinden (sarı çubuklar) . Mevcut çeyreğin 13 haftasında RMSFE’lerin gelişimi Kaynak: Ferrara ve Simoni (2023)
Üçüncüsü, çeyreğin ilk kamuoyu anketinin açıklandığı 5. haftadan başlayarak (euro bölgesi örneğinde) resmi veriler kullanıma sunulur sunulmaz, Google verilerinin göreli tahmin gücü hızla ortadan kalkar. Şekil 2’de, 5. hafta için tüm verileri içeren (turuncu çubuk) RMSFE’nin, herhangi bir Google verisi içermeyen RMSFE’ye (sarı çubuk) eşdeğer olduğunu görüyoruz. yalnızca çeyreğin ilk anketinde yer alan makro bilgilerle. Ayrıca, yalnızca Google verilerini (yeşil çubuklar) kullanan Ridge after Model Selection yaklaşımından kaynaklanan RMSFE’lerin fazla mesaide herhangi bir düşüş göstermediğini ve 5. haftadan itibaren turuncu çubuklarda görülen kazancın makro değişkenlerin entegrasyonundan kaynaklandığını öne sürüyoruz.
Dördüncüsü, durgunluk dönemleri, herhangi bir ön seçim içermeyen ve bilgi kümesi olarak yalnızca Google verilerinin kullanıldığı model olarak en düşük RMSFE’leri sağladığından (Şekil 3’teki yeşil çubuklar) belirli bir model sunar. Bu model, genel olarak Almanya ve ABD verileri için de görülebilir. Bu sonuç, ek araştırmalarla daha iyi anlaşılmalıdır, ancak durgunluklar sırasında gözlemlediğimiz iyi bilinen yüksek belirsizlikle ilgili olabilir, bu da onu açıklamak için daha fazla verinin kullanılması gerektiği anlamına gelir. Her halükarda bu, krizler sırasında alternatif verilerin kullanılmasının bir gerekçesi olarak görülebilir.
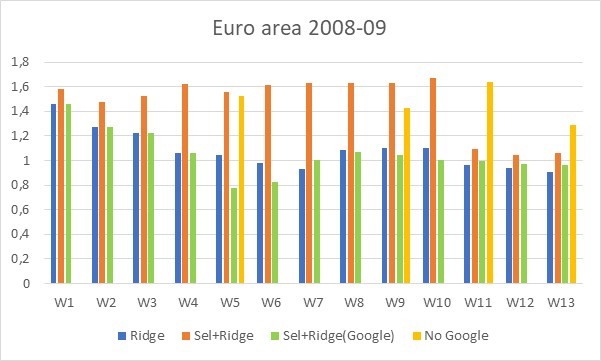
Figür 3: Bir durgunluk döneminde (2008-09) Euro bölgesi için RMSFE’ler, Ridge düzenlemesi (mavi çubuklar) ile standart bir regresyondan, Model Seçiminden Sonra Ridge yaklaşımından (turuncu çubuklar), yalnızca Google verilerini kullanan Model Seçiminden Sonra Ridge yaklaşımından kaynaklanmaktadır. (yeşil çubuklar) ve herhangi bir Google verisi olmayan temel bir regresyon modelinden (sarı çubuklar) . Mevcut çeyreğin 13 haftasında RMSFE’lerin gelişimi Kaynak: Ferrara ve Simoni (2023)
Çeşitli sağlamlık kontrolleri, bu ampirik sonuçların analizdeki tüm ülkeler/bölgeler için hala geçerli olduğunu ve 22 olağan değişkeni (satışlar, ihracat, istihdam, …) dikkate alarak makroekonomik bilgi setini artırdığımızda hala geçerli olduğunu doğrulamaktadır. Avro bölgesi için son olarak gerçek-gerçek bir analiz, çeşitli yaklaşımların sıralamasını doğrulamaktadır. Genel olarak, tüm bu sonuçlar, Google verilerinin, bir ön seçim adımından sonra bilgilerin eksik olduğu genişleme aşamalarında GSYİH büyümesinin şimdiki tahmini için çok yararlı olabileceğine işaret ediyor. Ancak, resmi makroekonomik bilgiler gelir gelmez, Google verilerinden elde edilen marjinal kazanç hızla yok olma eğilimindedir. Durgunluk evrelerinde, tahmincilerin ekonomik aktivitede neler olup bittiğini değerlendirmek için mevcut en geniş bilgi setine ihtiyacı var gibi görünüyor.
tarafından yazılan bu yazı laurent ferrara.