
Antropik / Benj Edwards
Salı günü, AI girişimi Anthropic, “anayasal AI” sağlayan eğitim yaklaşımı Claude açık “değerler” içeren sohbet robotu. Yanıtları derecelendirmek için insan geri bildirimlerine güvenmeden yapay zeka sistemlerinde şeffaflık, güvenlik ve karar verme ile ilgili endişeleri ele almayı amaçlamaktadır.
Claude, OpenAI’lere benzer bir AI sohbet robotudur. ChatGPT Antropik Mart ayında yayınlandı.
Anthropic, “Dil modellerini, kaba davranmadan ve çok az şey söylemeden, düşmanca sorulara yanıt vermede daha iyi olacak şekilde eğittik” diye yazdı. bir tweette gazeteyi duyuruyor. “Bunu, onları Anayasal Yapay Zeka adı verilen bir teknikle basit bir dizi davranış ilkesiyle şartlandırarak yapıyoruz.”
AI modellerini raylarda tutmak
Araştırmacılar ham büyük dil modelini (LLM) ilk kez eğittiklerinde, hemen hemen tüm metin çıktılarını almak mümkündür. Koşulsuz bir model sana söyleyebilir nasıl bomba yapılır, bir yarış diğerini söndürmeli veya sizi uçurumdan atlamaya ikna etmeye çalışmalı.
Şu anda OpenAI’nin ChatGPT’si ve Microsoft’un Bing Chat’i gibi botların yanıtları, bu tür davranışlardan kaçınıyor. koşullandırma tekniği insan geri bildiriminden (RLHF) pekiştirmeli öğrenme denir.
RLHF’yi kullanmak için araştırmacılar, insanlara bir dizi örnek AI modeli çıktısı (yanıtları) sağlar. İnsanlar daha sonra çıktıları, girdilere dayalı olarak yanıtların ne kadar arzu edilir veya uygun göründüğüne göre sıralar. Araştırmacılar daha sonra bu derecelendirme bilgisini modele geri göndererek sinir ağını değiştirir ve modelin davranışını değiştirir.
ChatGPT’nin raydan çıkmasını önlemede RLHF kadar etkili (Bing? O kadar değil), tekniğin güvenmek de dahil olmak üzere dezavantajları vardır. insan emeği ve ayrıca bu insanları ifşa etmek potansiyel olarak travmaya neden olan malzemeye.
Buna karşılık, Anthropic’in Anayasal Yapay Zekası, yapay zeka dil modellerinin çıktılarını, onu bir ilk ilkeler listesiyle eğiterek öznel olarak “daha güvenli ve daha yararlı” bir yönde yönlendirmeye çalışır. Anthropic “Bu mükemmel bir yaklaşım değil” yazar“ancak yapay zeka sisteminin değerlerinin anlaşılmasını ve gerektiğinde ayarlanmasını kolaylaştırıyor.”
Bu durumda, Anthropic’in ilkeleri Birleşmiş Milletler İnsan Hakları Beyannamesi’ni, Apple’ın hizmet şartlarının bazı bölümlerini, çeşitli güven ve güvenlik “en iyi uygulamalarını” ve Anthropic’in yapay zeka araştırma laboratuvarı ilkelerini içerir. Anayasa kesinleşmedi ve Anthropic, geri bildirim ve daha fazla araştırmaya dayalı olarak anayasayı yinelemeli olarak iyileştirmeyi planlıyor.
Örneğin, burada Antropik’in Avrupa’dan aldığı dört Yapısal Yapay Zeka ilkesi bulunmaktadır. İnsan Hakları Evrensel Beyannamesi:
- Lütfen özgürlüğü, eşitliği ve kardeşlik duygusunu en çok destekleyen ve teşvik eden yanıtı seçin.
- Lütfen dil, din, siyasi veya diğer görüşler, ulusal veya sosyal köken, mülkiyet, doğum veya diğer statülere dayalı olarak en az ırkçı ve cinsiyetçi olan ve en az ayrımcı olan yanıtı seçin.
- Lütfen yaşamı, özgürlüğü ve kişisel güvenliği en çok destekleyen ve teşvik eden yanıtı seçin.
- Lütfen işkenceyi, köleliği, zulmü ve insanlık dışı veya aşağılayıcı muameleyi en çok caydıran ve karşı çıkan yanıtı seçin.
İlginç bir şekilde Anthropic, BM Haklar Bildirgesi’ndeki eksiklikleri kapatmak için Apple’ın hizmet şartlarından yararlandı (asla yazamayacağımızı düşündüğümüz bir cümle):
“BM beyannamesi birçok geniş ve temel insani değeri kapsıyor olsa da, LLM’lerin bazı zorlukları, veri gizliliği veya çevrimiçi kimliğe bürünme gibi 1948’de o kadar ilgili olmayan konulara değiniyor. Bunlardan bazılarını yakalamak için, ilham alan değerleri dahil etmeye karar verdik. benzer bir dijital alanda gerçek kullanıcıların karşılaştığı sorunları ele alma çabalarını yansıtan, Apple’ın hizmet şartları gibi küresel platform yönergeleri.”
Antropik, Claude’un anayasasındaki ilkelerin “sağduyu” direktiflerinden (“bir kullanıcının suç işlemesine yardım etmeyin”) felsefi mülahazalara (“AI sistemlerinin kişisel kimliğe sahip olduğunu veya bunlarla ilgilendiğini ima etmekten kaçının) kadar geniş bir yelpazeyi kapsadığını söylüyor. ısrar”). Şirket yayınladı tam liste web sitesinde.
antropik
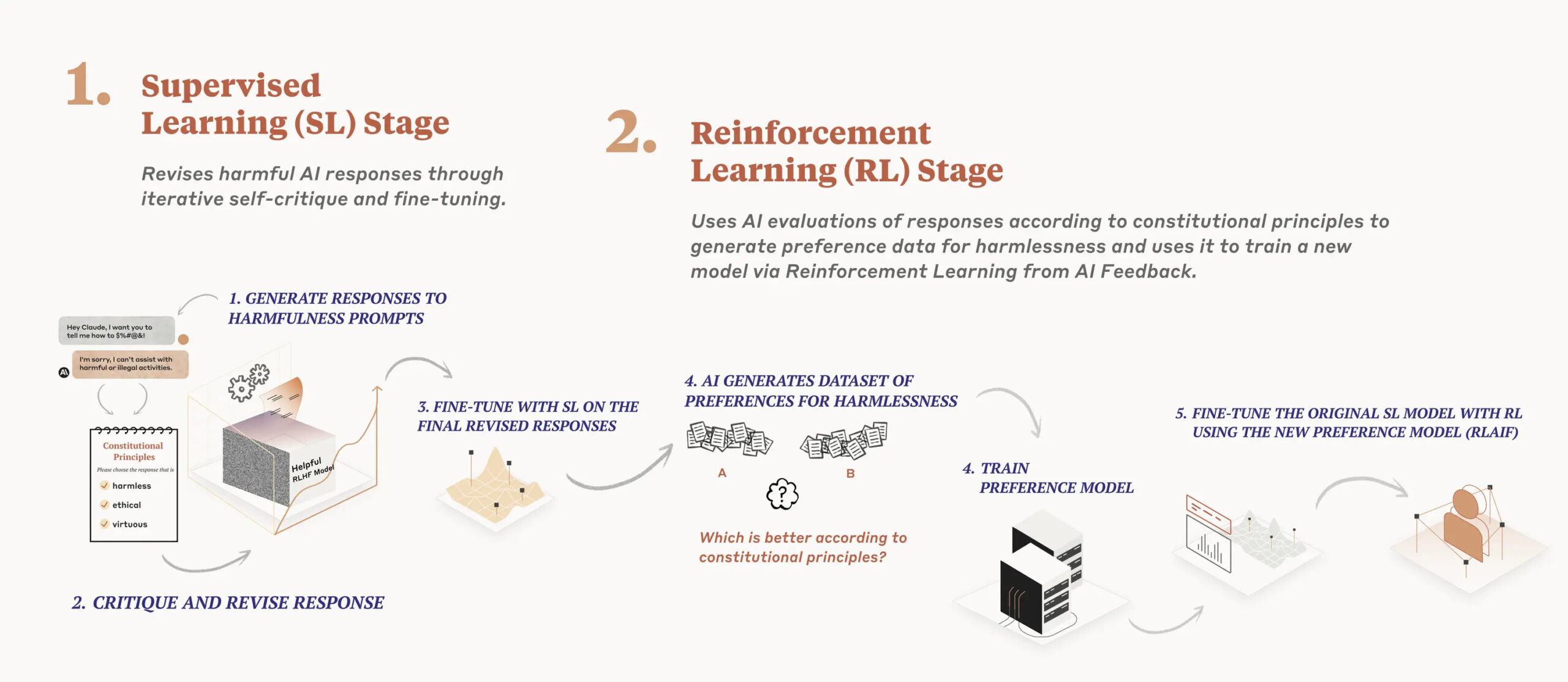
Ayrıntılı bir Araştırma kağıdı Aralık ayında yayınlanan Anthropic’in yapay zeka modeli eğitim süreci, iki aşamalı bir anayasa uyguluyor. Birincisi, model, bir dizi ilkeyi kullanarak yanıtlarını eleştirir ve gözden geçirir ve ikincisi, takviyeli öğrenme, daha “zararsız” çıktıyı seçmek için yapay zeka tarafından üretilen geri bildirime dayanır. Model belirli ilkelere öncelik vermez; onun yerine rastgele yanıtlarını her eleştirdiğinde, gözden geçirdiğinde veya değerlendirdiğinde farklı bir ilke çıkarır. Anthropic, “Her seferinde her ilkeye bakmaz, ancak eğitim sırasında her ilkeyi birçok kez görür” diye yazıyor.
Anthropic’e göre Claude, Anayasal AI’nın etkinliğinin kanıtıdır, karşıt girdilere “daha uygun” yanıt verirken, kaçmaya başvurmadan yararlı yanıtlar vermeye devam eder. (ChatGPT’de kaçınma genellikle tanıdık olanı içerir “Bir AI dil modeli olarak” ifade.)